Finding root cause in cloud computing
Steps to follow for finding root cause in cloud computing environment

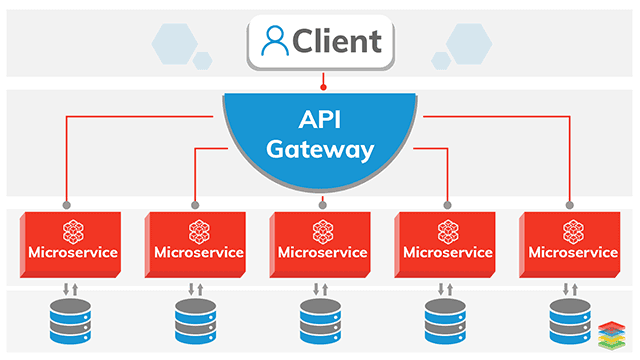
Cloud services have greatly expanded the IT capabilities available to support companies’ diverse business needs over the past few years. The home-grown software is being replaced by SaaS and company run data centres are being replaced with IaaS and PaaS offerings. While the move to the cloud brings significant benefits in business functionality, scalability and reducing capital costs, the management of these environments to provide service assurance to users can be challenging.
One of the areas that IT Service Management (ITSM) teams often struggle with is how to effectively diagnose issues and their causes when the symptoms, data and impacts extend beyond the boundaries of the organisations. Doing root cause analysis (RCA) in the cloud requires looking at the IT environment differently, taking a stronger dependency on data as a tool to help in analysis and knowing when to bring partners into the conversation to help.
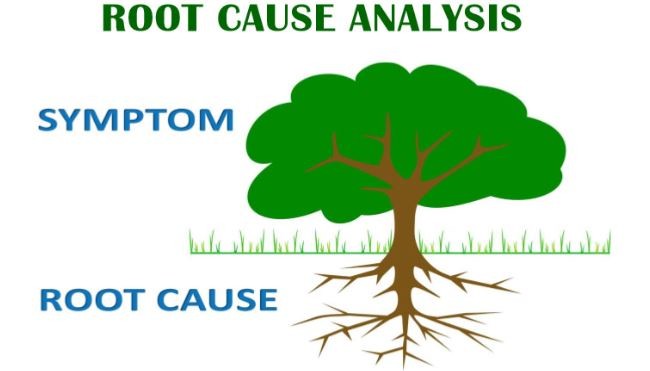
Below are a few tips that can help in performing root cause analysis in the cloud environment
1. Love & embrace automation
With cloud services, you don’t typically have access to source code for debugging software and you can’t physically touch most of the devices in the environment either. Monitoring and diagnosis of cloud environments require becoming a skilled user of automation to serve as your “eyes and ears”. Most cloud services have their own administrative tools which can help you understand what is going on inside the service itself, however, external monitoring and diagnostic capabilities might be necessary for monitoring the availability and performance of services to end-users.
One of the classic examples of using monitoring tools for investigation is where the users are getting affected by extreme slowness of Business applications. An approved change was implemented over the weekend and Major Incident Manager (MIM) is naturally drawn into that as a possible cause. However, if the organisation has a matured outlook then, a look at load time in Citrix shows that excessive latency is confined to roaming users. This could have easily picked up by the tool. Clearly no need to investigate the changes to the application!
2. Working with Partners
When we use cloud services, you aren’t just taking a dependency on the technology – you are extending your service operations to include the supplier organizations that provide and manage the services. When a problem is encountered that requires diagnosis and troubleshooting, the cloud provider should be there to assist. Often organisations don’t take help from their partners and rely of digging deeper in their own business application. I strongly believe to seek advantage of partners we have to do things differently to begin with.
First (and most challenging for most organisation) is acknowledging that troubleshooting isn’t an individual activity anymore but rather a team effort. You need to understand who is on the team and how to engage with them (I have struggled many times to find this bit of information with no clear guidelines of the correct accountability).
The second thing we need to do differently is to understand your Service Level Agreements (the formal contracts with suppliers) to ensure they are prepared to provide the responsiveness and resources at the time of service disruption or finding out the root cause.
Our partners also have an interest in helping us a long duration incident is not only a nuisance to our users, but it’s also consuming partner’s time in diagnosing the fault. The more effectively the whole partner ecosystem co-operates, the better for everyone.
I would always love to add the incident investigation in their contractual obligation to furnish a root cause for every Major Incident. Knowing that they have to provide a detailed, credible explanation will influence the way they treat incident investigations for the better.
3. The inherent Service Interfaces
Cloud services are meant to be treated as “black boxes” with the details of what goes into providing the service only available to the service providers (obscured from our view). This can be a good thing as it makes your IT environment much less complex. For some IT staff members, not seeing how things work can be frustrating. The key is learning to focus on managing the scope and interfaces for the service – understanding what is going in, and what is coming out of the box along with the functions that are expecting to be performed within the service. Managing service interfaces may require some changes to your company’s notion of what configuration items are in your CMDB (configuration management database), what needs to be monitored, and how SLAs should be structured, but yes only if you have a functional & reliable CMDB
4. Understand the composition of a Service
Just because you can’t see the detailed inter working of a cloud service, doesn’t eliminate the need for a basic understanding of what the services you use are composed of. Most cloud services include dependencies on the underlying technology, connectivity from external service providers and other cloud services (like hosting or data storage). It is important to understand (at a high level) what these dependencies are even if you don’t manage them directly. They still present a potential cause of failure that needs to be considered in the root cause analysis process.
5. Don’t forget about connectivity
When using cloud services, you need to pay special attention to the connectivity components that enable users and administrators to access the services. It’s great if the service is up and running but if you can’t get to it, you still have a problem. The same tip applies to monitoring and diagnostic tools. If the only tools you have available are hosted by the service provider, you may not be able to access them in the event of a connectivity issue.
For the last couple of years, one of the biggest advances in the IT industry is managing IT infrastructure in cloud services and this provides exceptional productivity and cost savings for customers and organisations. Thus this definitely requires IT management staff to think differently of our approach to manage, monitor and repair our services when it disrupts
Cloud services are one of the biggest advances in the IT industry over the past 5 years and provide tremendous productivity and cost-saving potential for companies that use them. They do require your IT service management staff to think differently about how they manage, monitor and repair issues when they occur.